
Building a real-time big data pipeline (4: Spark Streaming, Kafka, Scala)
Published:
Updated on January 19, 2021
Apache Kafka is a scalable, high performance and low latency platform for handling of real-time data feeds. Kafka allows reading and writing streams of data like a messaging system; written in Scala and Java.
Kafka requires Apache Zookeeper to run. Kafka v2.5.0 (scala v2.12 build) and zookeeper (v3.4.13) were installed using docker.
See my other blogs for installations Kafka and Zookeeper with Docker; The Scala Build Tool (SBT) on macOS
Once we start Zookeeper and Kafka locally, we can proceed to create our first topic, named “mytopic”:
bash-4.4# ./kafka-topics.sh \
--create \
--topic mytopic \
--partitions 1 \
--replication-factor 1 \
--bootstrap-server localhost:9092
Spark Streaming is an extension of the core Apache Spark platform that enables scalable, high-throughput, fault-tolerant processing of data streams; written in Scala but offers Scala, Java, R and Python APIs to work with. It takes data from the sources like Kafka, Flume, Kinesis, HDFS, S3 or Twitter. This data can be further processed using complex algorithms. The final output, which is the processed data can be pushed out to destinations such as HDFS filesystems, databases, and live dashboards. Spark Streaming allows you to use Machine Learning applications to the data streams for advanced data processing. Spark uses Hadoop’s client libraries for distributed storage (HDFS) and resource management (YARN).
See my other blog for Hadoop installation and moving files from local to Hadoop Distributed File System (HDFS).
Figure source https://www.cuelogic.com
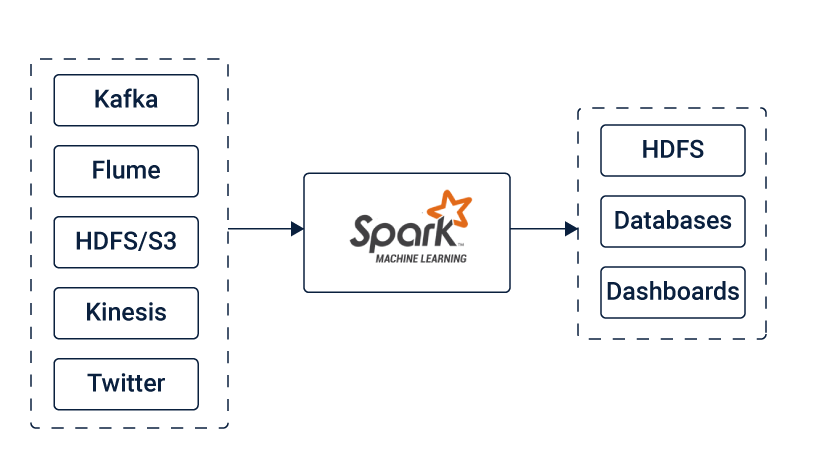
It’s very important to assemble the compatible versions of all of these. Download, and unzip, Spark 3.0.0 pre-built for hadoop 3.2 and later version (with Scala 2.12 compatibility); then add env variables to ~/.bash_profile as
export SPARK_HOME="/<path_to_installation_dir>/spark-3.0.0-bin-hadoop3.2"
export PATH="$PATH:$SPARK_HOME/bin"
Once the right package of Spark is unpacked, your will need to add the following jars in the $SPARK_HOME/jars directory. It’s important to choose the right package depending upon the broker available (eg. Kafka) and features desired. We can pull the following dependencies from Maven Central:
1. commons-pool2-2.8.0.jar
2. kafka-clients-2.5.0.jar
3. spark-sql-kafka-0-10_2.12-3.0.0-preview2.jar
4. spark-token-provider-kafka-0-10_2.12-3.0.0-preview2.jar
5. spark-streaming-kafka-0-10_2.12-3.0.0-preview2.jar
6. kafka_2.12-2.5.0.jar
Scala Application
Start the spark-shell (for Scala) using the following command
$spark-shell
In case the installation happened successfully, the above command will start Apache Spark in Scala. Create a simple application in Scala using Spark which will integrate with the Kafka topic we created earlier. The application will read the messages as posted.
In the Spark shell, a special interpreter-aware SparkContext is already created for you, in the variable called sc. Stop SparkContext and create StreamingContext. You can create a StreamingContext by using an existing SparkContext or by providing the configuration (conf) necessary for a new one
sc.stop
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
val conf = new SparkConf().setMaster("local[*]").setAppName("kafkaReceiver")
val streamingContext = new StreamingContext(conf, Seconds(10))
Now, we can connect to the Kafka topic from the StreamingContext. Please note that we’ve to provide deserializers for key and value here. For common data types like String, the deserializer is available by default. However, if we wish to retrieve custom data types, we’ll have to provide custom deserializers.
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark-streaming-consumer-group",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean))
val topics = Array("mytopic")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams))
Spark Streaming provides a high-level abstraction that represents a continuous data stream. This abstraction of the data stream is called discretized stream or DStream. This DStream can either be created from the data streams from the sources such as Kafka, Flume, and Kinesis or other DStreams by applying high-level operations on them.
Here, we’ve obtained InputDStream which is an implementation of Discretized Streams or DStreams, the basic abstraction provided by Spark Streaming. Internally DStreams is nothing but a continuous series of RDDs (Resilient Distributed Dataset).
Figure source https://www.cuelogic.com
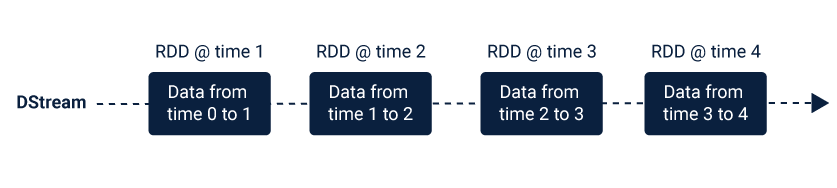
We’ll now perform a series of operations on the InputDStream to obtain our messages. As this is a stream processing application, we would want to keep this running:
stream.map(record=>(record.value().toString)).print
streamingContext.start
streamingContext.awaitTermination()
Once we start this application and post some messages in the Kafka topic we created earlier,
>bash-4.4# ./kafka-console-producer.sh
--broker-list localhost:9092
--topic mytopic
>hello
>here is my message
we should see the messages like …
-------------------------------------------
Time: 1593889650000 ms
-------------------------------------------
hello
-------------------------------------------
Time: 1593889670000 ms
-------------------------------------------
here is my message
Finally, to exit from scala shell
scala> :q
You can shut down docker-compose by executing the following command in another terminal.
bash-4.4# exit
$docker-compose down