
Building a real-time big data pipeline (3: Spark SQL, Hadoop, Scala)
Published:
Updated on June 22, 2020
Apache Spark is an open-source cluster computing system that provides high-level API in Java, Scala, Python and R.
Spark also packaged with higher-level libraries for SQL, machine learning, streaming, and graphs. Spark SQL is Spark’s package for working with structured data 1.
1. Hadoop - copy a .csv file to HDFS
The Hadoop Distributed File System (HDFS) is the primary data storage system used by Hadoop applications. It employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters.2
cd hadoop-3.1.3/
$bash sbin/start-dfs.sh
$hadoop fs -mkdir -p /user/adinasarapu
Use -copyFromLocal command to move one or more files from local location to HDFS.
$hadoop fs -copyFromLocal *.csv /user/adinasarapu
$hadoop fs -ls /user/adinasarapu
-rw-r--r-- 1 adinasarapu supergroup 1318 2020-02-13 21:41 /user/adinasarapu/samples.csv
-rw-r--r-- 1 adinasarapu supergroup 303684 2020-02-14 09:33 /user/adinasarapu/survey.csv
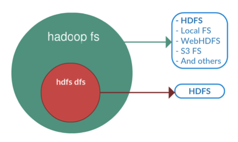
hadoop fs is more generic command that allows you to interact with multiple file systems like local, HDFS etc. This can be used when you are dealing with different file systems such as local FS, (S)FTP, S3, and others.
hdfs dfs is the command that is specific to HDFS.
$hdfs dfs -ls /user/adinasarapu
-rw-r--r-- 1 adinasarapu supergroup 1318 2020-02-15 10:02 samples.csv
-rw-r--r-- 1 adinasarapu supergroup 303684 2020-02-15 10:02 survey.csv
Figure. Hadoop filesystem.
For Hadoop Architecture in Detail – HDFS, Yarn & MapReduce
$bash start-yarn.sh
Starting resourcemanager
Starting nodemanagers
Check the list of Java processes running in your system by using the command jps. If you are able to see the Hadoop daemons running after executing the jps command, we can safely assume that the Hadoop cluster is running.
$jps
96899 NodeManager
91702 SecondaryNameNode
96790 ResourceManager
97240 Jps
91437 NameNode
91550 DataNode
We can stop all the daemons using the command stop-all.sh. We can also start or stop each daemon separately.
$bash stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as adinasarapu in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [Ashoks-MacBook-Pro.local]
Stopping nodemanagers
Stopping resourcemanager
Web UI
for HDFS: http://localhost:9870
for YARN Resource Manager: http://localhost:8088
Note: Hadoop can be installed in 3 different modes: standalone mode, pseudo-distributed mode and fully distributed mode. In fully distributed mode, replace the ‘’localhost’ with actual host name of machine on cluster.
2. Read a csv file (from HDFS) into Spark DataFrame
A Spark DataFrame can be constructed from an array of data sources such as Hive tables, Structured Data files (ex.csv), external databases (eg. MySQL), or existing RDDs.
Start Hadoop and Spark
$bash start-dfs.sh
$spark-shell
Read csv file into a Spark DataFrame
scala> val df = spark.read.format("csv")
.option("header", "true")
.option("inferSchema","true")
.option("nullValue","NA")
.option("mode","failfast")
.load("hdfs://localhost:9000/user/adinasarapu/samples.csv")
For more details visit Spark Read CSV file into DataFrame
Select & filter the Spark DataFrame
scala> val sel = df.select("Sample","p16","Age","Race").filter($"Anatomy".like("BOT"))
What does dollar sign do here in scala? So, basically, you are making it a variable(of type Column) with $"" in Spark.
scala> sel.show
+------+--------+---+-----+
|Sample| p16|Age| Race|
+------+--------+---+-----+
|GHN-48|Negative| 68|white|
|GHN-57|Negative| 50|white|
|GHN-62|Negative| 71|white|
|GHN-39|Positive| 51|white|
|GHN-60|Positive| 41|white|
|GHN-64|Positive| 49|white|
|GHN-65|Positive| 63|white|
|GHN-69|Positive| 56|white|
|GHN-70|Positive| 68|white|
|GHN-71|Positive| 59|white|
|GHN-77|Positive| 53| AA|
|GHN-82|Positive| 67|white|
|GHN-43|Positive| 65|white|
+-------------------------+
Spark DataFrame Schema:
Schema is definition for the column name and it’s data type. In Spark, the data source defines the schema, and we infer it from the source. Spark Data Frame always uses Spark types (org.apache.spark.sql.types)
To check the Schema of Spark DataFrame use the following command.
scala> println(df.schema)
Alternatively, a user can define the schema explicitly and read the data using user defined schema definition (when data source is csv or json files).
If you know the schema of the file ahead and do not want to use the inferSchema option for column names and types, use user-defined custom column names and type using schema option.
scala> import org.apache.spark.sql.types._
scala> val sampleSchema = new StructType()
.add("Sample",StringType,true)
.add("p16",StringType,true)
.add("Age",IntegerType,true)
.add("Race",StringType,true)
.add("Sex",StringType,true)
.add("Anatomy",StringType,true)
.add("Smoking",StringType,true)
.add("Radiation",StringType,true)
.add("Chemo",StringType,true)
scala> val df = spark.read.format("csv")
.option("header", "true")
.option("schema","sampleSchema")
.option("nullValue","NA")
.option("mode","failfast")
.load("hdfs://localhost:9000/user/adinasarapu/samples.csv")
scala> df.printSchema()
root
|-- Sample: string (nullable = true)
|-- p16: string (nullable = true)
|-- Age: string (nullable = true)
|-- Race: string (nullable = true)
|-- Sex: string (nullable = true)
|-- Anatomy: string (nullable = true)
|-- Smoking: string (nullable = true)
|-- Radiation: string (nullable = true)
|-- Chemo: string (nullable = true)
scala> val df = df.select("sample","Age","Sex","Anatomy")
.filter($"Anatomy".contains("BOT") and $"Age" > 55)
scala> df.show
+------+---+------+-------+
|sample|Age| Sex|Anatomy|
+------+---+------+-------+
|GHN-48| 68|female| BOT|
|GHN-62| 71| male| BOT|
|GHN-65| 63| male| BOT|
|GHN-69| 56| male| BOT|
|GHN-70| 68| male| BOT|
|GHN-71| 59| male| BOT|
|GHN-82| 67| male| BOT|
|GHN-43| 65| male| BOT|
+------+---+------+-------+
Write the resulting DataFrame back to HDFS
scala> df.write.option("header","true")
.csv("hdfs://localhost:9000/user/adinasarapu/samples_filtered.csv")
$hadoop fs -ls
-rw-r--r-- 1 adinasarapu supergroup 1318 2020-02-13 21:41 samples.csv
drwxr-xr-x - adinasarapu supergroup 0 2020-02-14 10:39 samples_filtered.csv
-rw-r--r-- 1 adinasarapu supergroup 303684 2020-02-14 09:33 survey.csv
overwrite – mode is used to overwrite the existing file, alternatively, you can use SaveMode.Overwrite.
scala> df.write.option("header","true")
.mode("overwrite")
.csv("hdfs://localhost:9000/user/adinasarapu/samples_filtered.csv")
OR
scala> import org.apache.spark.sql.SaveMode
scala> df.write.option("header","true")
.mode(SaveMode.Overwrite)
.csv("hdfs://localhost:9000/user/adinasarapu/samples_filtered.csv")
To list all the files within a hdfs directory using Hadoop command
$hdfs dfs -ls /user/adinasarapu
OR
$hadoop fs -ls /user/adinasarapu
To list all the files within a hdfs directory using Scala/Spark.
scala> import java.net.URI
scala> import org.apache.hadoop.conf.Configuration
scala> import org.apache.hadoop.fs.{FileSystem, Path}
scala> val uri = new URI("hdfs://localhost:9000")
scala> val fs = FileSystem.get(uri,new Configuration())
scala> val filePath = new Path("/user/adinasarapu/")
scala> val status = fs.listStatus(filePath)
scala> status.map(sts => sts.getPath).foreach(println)
hdfs://localhost:9000/user/adinasarapu/samples.csv
hdfs://localhost:9000/user/adinasarapu/select.csv
hdfs://localhost:9000/user/adinasarapu/survey.csv
3. Temporary Views
“The life of a Spark Application starts and finishes with the Spark Driver. The Driver is the process that clients use to submit applications in Spark. The Driver is also responsible for planning and coordinating the execution of the Spark program and returning status and/or results (data) to the client. The Driver can physically reside on a client or on a node in the cluster. The Spark Driver is responsible for creating the SparkSession.” - Data Analytics with Spark Using Python
“Spark Application and Spark Session are two different things. You can have multiple sessions in a single Spark Application. Spark session internally creates a Spark Context. Spark Context represents connection to a Spark Cluster. It also keeps track of all the RDDs, Cached data as well as the configurations. You can’t have more than one Spark Context in a single JVM. That means, one instance of an Application can have only one connection to the Cluster and hence a single Spark Context. In standard applications you may not have to create multiple sessions. However, if you are developing an application that needs to support multiple interactive users you might want to create one Spark Session for each user session. Ideally we should be able to create multiple connections to Spark Cluster for each user. But creating multiple Contexts is not yet supported by Spark.” - Learning Journal3
Convert Spark DataFrame into temporary view that is available for only that spark session (local) or across spark sessions (global) within the current application. The session-scoped view serve as a temporary table on which SQL queries can be made. There are two broad categories of DataFrame methods to create a view:
Local Temp View: Visible to the current Spark session. a). createOrReplaceTempView b). createTempView
Global Temp View: Visible to the current application across the Spark sessions.
a). createGlobalTempView
b). createOrReplaceGlobalTempView
“We can have multiple spark contexts by setting spark.driver.allowMultipleContexts to true. But having multiple spark contexts in the same JVM is not encouraged and is not considered as a good practice as it makes it more unstable and crashing of 1 spark context can affect the other.” - A tale of Spark Session and Spark Context4
Create a local temporary table view
scala> df.createOrReplaceTempView("sample_tbl")
spark.catalog.listTables() tries to fetch every table’s metadata first and then show the requested table names.
scala> spark.catalog.listTables.show
+----------+--------+-----------+---------+-----------+
| name|database|description|tableType|isTemporary|
+----------+--------+-----------+---------+-----------+
|sample_tbl| null| null|TEMPORARY| true|
+----------+--------+-----------+---------+-----------+
scala> df.cache()
There are two function calls for caching an RDD: cache() and persist(level: StorageLevel). The difference among them is that cache() will cache the RDD into memory, whereas persist(level) can cache in memory, on disk, or off-heap memory according to the caching strategy specified by level. persist() without an argument is equivalent with cache().
scala> val resultsDF = spark.sql("SELECT * FROM sample_tbl WHERE Age > 70")
scala> resultsDF.show
+------+--------+---+-----+------+-------+-------+---------+-----+
|Sample| p16|Age| Race| Sex|Anatomy|Smoking|Radiation|Chemo|
+------+--------+---+-----+------+-------+-------+---------+-----+
|GHN-62|Negative| 71|white| male| BOT| never| Y| N|
|GHN-73|Positive| 72|white|female| Tonsil| never| Y| Y|
+------+--------+---+-----+------+-------+-------+---------+-----+
Create a global temporary table view
scala> df.createOrReplaceGlobalTempView("sample_gtbl")
sample_gtbl belongs to system database called global_temp. This qualified name should be used to access GlobalTempView(global_temp.sample_gtbl) or else it throws an error Table or view not found. When you run spark.catalog.listTables.show, if you don’t specify the database for the listTables() function it will point to default database. Try this instead:
scala> spark.catalog.listTables("global_temp").show
+-----------+-----------+-----------+---------+-----------+
| name| database|description|tableType|isTemporary|
+-----------+-----------+-----------+---------+-----------+
|sample_gtbl|global_temp| null|TEMPORARY| true|
| sample_tbl| null| null|TEMPORARY| true|
+-----------+-----------+-----------+---------+-----------+
scala> val resultsDF = spark.sql("SELECT * FROM global_temp.sample_gtbl WHERE Age > 70")
scala> resultsDF.show
+------+---+----+-------+
|sample|Age| Sex|Anatomy|
+------+---+----+-------+
|GHN-62| 71|male| BOT|
+------+---+----+-------+
4. Read a MySQL table data file into Spark DataFrame
At the command line, log in to MySQL as the root user:5
$mysql -u root -p
Type the MySQL root password, and then press Enter.
To create a new MySQL user account, run the following command:
$mysql> CREATE USER 'adinasarapu'@'localhost' IDENTIFIED BY 'xxxxxxx';
$mysql> GRANT ALL PRIVILEGES ON *.* TO 'adinasarapu'@'localhost';
$mysql -u adinasarapu -p`
Type the MySQL user’s password, and then press Enter.
$mysql> SHOW DATABASES;
$mysql> CREATE DATABASE meta;
$mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| meta |
| mysql |
| performance_schema |
+--------------------+
To work with the new database, type the following command.
mysql> USE meta;
mysql> CREATE TABLE samples (
-> Sample VARCHAR(20) NOT NULL,
-> p16 VARCHAR(20) NOT NULL,
-> Age INT,
-> Race VARCHAR(20) NOT NULL,
-> Sex VARCHAR(20) NOT NULL,
-> Anatomy VARCHAR(20) NOT NULL,
-> Smoking VARCHAR(20) NOT NULL,
-> Radiation VARCHAR(20) NOT NULL,
-> Chemo VARCHAR(20) NOT NULL,
-> PRIMARY KEY ( Sample )
-> );
mysql> LOAD DATA LOCAL INFILE '/Users/adinasarapu/spark_example/samples.csv'
INTO TABLE samples FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n' IGNORE 1 ROWS;
If you encounter the following error
ERROR 3948 (42000): Loading local data is disabled; this must be enabled on both the client and server sides
Add local_infile = 1 to the [mysqld] section of the /etc/my.cnf file and restart the mysqld service.
$sudo vi /etc/my.cnf
$mysql -u root -p --local_infile=1
mysql> SHOW GLOBAL VARIABLES LIKE 'local_infile';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| local_infile | ON |
+---------------+-------+
mysql> USE meta;
mysql> LOAD DATA LOCAL INFILE '/Users/adinasarapu/spark_example/samples.csv'
INTO TABLE samples FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n' IGNORE 1 ROWS;
mysql> SELECT * FROM samples;
+--------+----------+-----+-------+--------+---------+---------+-----------+---------+
| Sample | p16 | Age | Race | Sex | Anatomy | Smoking | Radiation | Chemo |
+--------+----------+-----+-------+--------+---------+---------+-----------+---------+
| GHN-39 | Positive | 51 | white | male | BOT | never | Y | Y |
| GHN-40 | Positive | 66 | white | male | Tonsil | former | Y | Y |
| GHN-43 | Positive | 65 | white | male | BOT | former | Y | Y |
| GHN-48 | Negative | 68 | white | female | BOT | current | Y | Y |
| GHN-53 | Unknown | 58 | white | male | Larynx | current | Y | Y |
| GHN-57 | Negative | 50 | white | female | BOT | current | Y | Y |
| GHN-84 | Positive | 56 | white | male | Tonsil | never | Y | N |
| ... | ... | .. | ... | ... | ... | ... | ... | ... |
+--------+----------+-----+-------+--------+---------+---------+-----------+---------+
Create a new MySQL table from Spark DataFrame
scala> import org.apache.spark.sql.SaveMode
scala> val prop = new java.util.Properties
scala> prop.setProperty("driver", "com.mysql.cj.jdbc.Driver")
scala> prop.setProperty("user", "root")
scala> prop.setProperty("password", "pw")
scala> val url = "jdbc:mysql://localhost:3306/meta"
scala> df.write.mode(SaveMode.Append).jdbc(url,"newsamples",prop)
If you see MySQL JDBC Driver - Time Zone Issue, change url to
scala> val url = "jdbc:mysql://localhost/meta?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC"
mysql> USE meta;
mysql> SHOW tables;
+----------------+
| Tables_in_meta |
+----------------+
| newsamples |
| samples |
+----------------+
Finally, exit mysql, scala and hadoop
mysql>exit
scala>:q
bash stop-all.sh