
Building a real-time big data pipeline (10: Spark Streaming, Kafka, Java)
Published:
Updated on February 08, 2021
Apache Kafka is a scalable, high performance and low latency platform for handling of real-time data feeds. Kafka allows reading and writing streams of data like a messaging system; written in Scala and Java. Kafka requires Apache Zookeeper which is a coordination service that gives you the tools you need to write correct distributed applications. You need to have Java installed before running ZooKeeper. Kafka v2.5.0 (scala v2.12 build) and zookeeper (v3.4.13) were installed using docker.
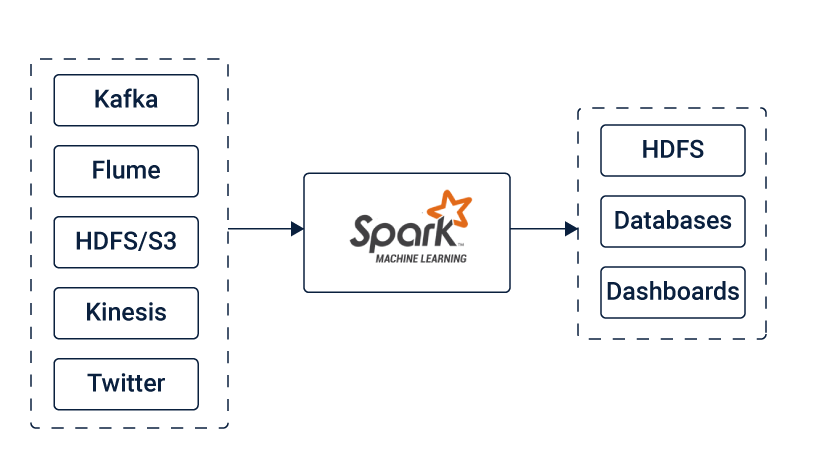
Spark Streaming is an extension of the core Apache Spark platform that enables scalable, high-throughput, fault-tolerant processing of data streams; written in Scala but offers Scala, Java, R and Python APIs to work with. It takes data from the sources like Kafka, Flume, Kinesis, HDFS, S3 or Twitter. This data can be further processed using complex algorithms. The final output, which is the processed data can be pushed out to destinations such as HDFS filesystems, databases, and live dashboards. Spark Streaming allows you to use Machine Learning applications to the data streams for advanced data processing. Spark uses Hadoop’s client libraries for distributed storage (HDFS) and resource management (YARN).
Figure source https://www.cuelogic.com
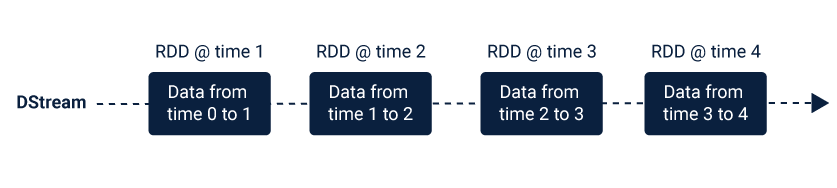
Spark Streaming provides a high-level abstraction that represents a continuous data stream. This abstraction of the data stream is called discretized stream or DStream. This DStream can either be created from the data streams from the sources such as Kafka, Flume, and Kinesis or other DStreams by applying high-level operations on them.
Figure source https://www.cuelogic.com
Kafka installation
See my other blog for installation and starting kafka service Kafka and Zookeeper with Docker.
First install docker desktop and create docker-compose.yml file for Zookeeper and Kafka services. The first image is zookeeper (this service listens to port 2181). Kafka requires zookeeper to keep track of various brokers. The second service is kafka itself and here we are just running a single instance of it i.e one broker. Ideally, you would want to use multiple brokers in order to leverage the distributed architecture of Kafka.
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: localhost
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
The kafka service environment variables.
KAFKA_ADVERTISED_HOST_NAME: localhost
This is the address at which Kafka is running, and where producers and consumers can find it).
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
This is for the hostname and port number of your zookeeper service. We named hostname as zookeeper.
Run the following commands in the directory where docker-compose.yml file is present.
docker-compose up -d
docker-compose exec kafka bash
Change the directory to /opt/kafka/bin where you find scripts such as kafka-topics.sh.
The Kafka cluster stores streams of records in categories called topics. Once we start zookeeper and kafka locally, we can proceed to create our first topic, named mytopic. The producer clients can then publish streams of data (messages) to the said topic (mytopic) and consumers can read the said datastream, if they are subscribed to that particular topic.
bash-4.4# ./kafka-topics.sh \
--create \
--topic mytopic \
--partitions 1 \
--replication-factor 1 \
--bootstrap-server localhost:9092
A Kafka topic is divided into one or more partitions. A partition contains an unchangeable sequence of records/messages. Each record/message in a partition is assigned and identified by its unique offset. If you set replication factor of a topic as 3, i.e., there will always be three copies of your data. This replication is performed at the level of topic-partitions.
To verify a topic’s partitions and replication factor:
bash-4.4# ./kafka-topic.sh --zookeeper localhost:2181 --topic mytopic --describe
Java Application
Create a new Maven enabled project in Eclipse IDE and update the pom.xml file for spark-core, spark-streaming, spark-streaming-kafka and spark-sql libraries.
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
Create a Java class with the following content
package com.example.spark;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
public class JavaSparkApp {
public static void main(String[] args) throws InterruptedException {
// Firstly, we'll begin by initializing the JavaStreamingContext which is the entry point for all Spark Streaming applications:
Logger.getLogger("org").setLevel(Level.ALL);
Logger.getLogger("akka").setLevel(Level.ALL);
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local");
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
sparkConf.setAppName("WordCountingApp");
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(1));
// Now, we can connect to the Kafka topic from the JavaStreamingContext.
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "localhost:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "group_test2");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
Collection<String> topics = Arrays.asList("mytopic");
JavaInputDStream<ConsumerRecord<String, String>> messages = KafkaUtils.createDirectStream(streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams));
JavaDStream<String> data = messages.map(v -> { return v.value(); });
data.print();
streamingContext.start();
streamingContext.awaitTermination();
}
}
Compile/run the above cretaed Java class and then run the console producer to write a few events into your topic.
>bash-4.4# ./kafka-console-producer.sh
--broker-list localhost:9092
--topic mytopic
>hello
>here is my message
The above (producer) messages will be published in Eclipse console as …
-------------------------------------------
Time: 1593889650000 ms
-------------------------------------------
hello
-------------------------------------------
Time: 1593889670000 ms
-------------------------------------------
here is my message
You now have a rough picture of how Kafka and Spark Streaming works. For your own use case, you need to set a hostname which is not localhost, you need multiple such brokers to be a part of your kafka cluster and finally you need to set up a producer client application like the above java consumer client application.
You can shut down docker-compose by executing the following command in another terminal.
bash-4.4# exit
$docker-compose down
Useful links
The Power of Kafka Partitions : How to Get the Most out of Your Kafka Cluster by Paul Brebner
Deploy Apache Kafka using Docker Compose by Ranvir Singh